Analytical approaches
Working with FHIR Data
Healthcare data retrieved from FHIR servers is inherently hierarchical, reflecting the relationships between patients, encounters, observations and other clinical entities. While this model excels at representing real-world workflows, it can complicate analytics: extracting a simple list of patient diagnoses may require traversing multiple layers of nested JSON.
Several strategies have emerged to simplify FHIR data for analysis:
- Direct RESTful Queries
- Description: Clients issue HTTP GET requests against FHIR endpoints (e.g.
/Observation?patient=123) to retrieve raw resources.
- Shortcomings:
- Results remain deeply nested JSON, requiring custom parsing logic.
- Related resources often require additional round-trips (e.g. follow-up requests to fetch linked Patient or Encounter).
- Performance can degrade when paging through large result sets.
- Results remain deeply nested JSON, requiring custom parsing logic.
- Description: Clients issue HTTP GET requests against FHIR endpoints (e.g.
- FHIRPath Expressions
- Description: FHIRPath is a domain-specific language for navigating and extracting data from FHIR resources (e.g.
Observation.where(code = 'XYZ').value).
- Shortcomings:
- Engine support varies by server; not all servers expose a FHIRPath execution endpoint.
- Complex expressions become hard to maintain for broad analytic queries.
- Performance may suffer when evaluating on large collections.
- Engine support varies by server; not all servers expose a FHIRPath execution endpoint.
- Description: FHIRPath is a domain-specific language for navigating and extracting data from FHIR resources (e.g.
- Clinical Quality Language (CQL)
- Description: CQL is a higher-level, human-readable language designed for clinical decision support and quality measurement; it can query and compute over FHIR data.
- Shortcomings:
- Primarily intended for clinical rules rather than ad-hoc analytics.
- Requires a CQL execution engine (e.g. on a CDS server).
- Steeper learning curve for analytics teams accustomed to SQL.
- Primarily intended for clinical rules rather than ad-hoc analytics.
- Description: CQL is a higher-level, human-readable language designed for clinical decision support and quality measurement; it can query and compute over FHIR data.
- SQL-on-FHIR
- Description: This approach flattens nested FHIR resources into relational tables or views, enabling analysts to use standard SQL to query FHIR data as if it were in a traditional data warehouse.
- Shortcomings:
- Initial setup requires mapping FHIR structures to tables
- May lose some of the hierarchical semantics and provenance metadata.
- Ongoing maintenance needed as resource profiles evolve.
- Description: This approach flattens nested FHIR resources into relational tables or views, enabling analysts to use standard SQL to query FHIR data as if it were in a traditional data warehouse.
Each method balances trade-offs between real-time access, complexity, performance, and maintenance. In practice, many organizations combine bulk export for periodic batch processing with SQL-on-FHIR or dbt for ongoing analytics, reserving FHIRPath or CQL for domain-specific rule evaluations.
The method that was best suited to generate the required metrics was bulk exports of FHIR data in NDJSON files, using SQL-ON-FHIR to flatten the tables and dbt for analytics.
SQL-on-FHIR
Within the Open Health Stack (OHS) Analytics framework, two primary strategies exist for “flattening” FHIR resources into analytics‐ready tables:
- SQL Virtual Views
- Analysts write SQL statements against raw FHIR exports (e.g., Parquet files) to define virtual views.
- These views live outside the core ETL pipeline, in the downstream SQL engine, and can be modified independently.
- Analysts write SQL statements against raw FHIR exports (e.g., Parquet files) to define virtual views.
- FHIR ViewDefinition Resources
- The SQL-on-FHIR-v2 spec introduces a
ViewDefinitionresource that uses FHIRPath expressions to map nested elements into columns.
- An OHS “View Runner” within the pipeline materializes these definitions into persistent tables.
- The SQL-on-FHIR-v2 spec introduces a
The ValuePoints solution adopts the SQL-on-FHIR approach, a nascent standard that provides portable, version-controlled view definitions and seamless integration with downstream analytics platforms.
ETL Pipeline Overview
The ValuePoints ETL pipeline includes a Base Reporter module that leverages SQL-on-FHIR to extract event-level data from FHIR resources and assemble a canonical patient timeline. That timeline then serves as the foundation for all subsequent metric computation and reporting.
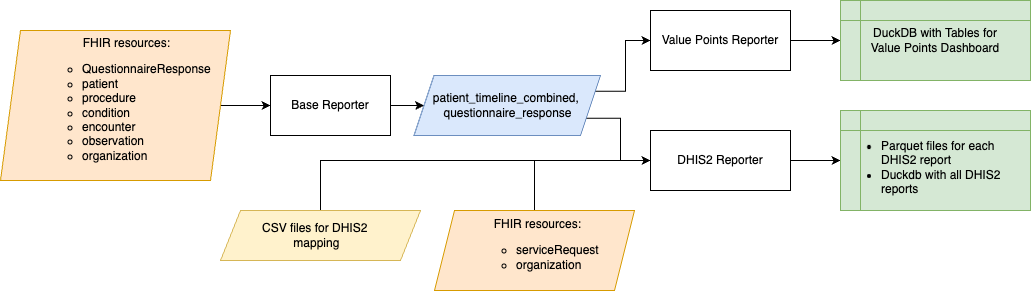
Patient Timeline Table
The Patient Timeline table captures each clinical event—procedures, treatments, diagnoses—alongside standardized timestamps and contextual metadata. By reconstructing the sequence of a patient’s interactions over time, this table enables longitudinal analysis and supports all downstream reports.
DHIS2 Reporter
As an additional validation of the Patient Timeline approach, the DHIS2 Reporter module produces MNCH-specific DHIS2–compatible reports directly from the canonical timeline. By reusing the same event-level data source:
- Consistency is ensured across all analytics outputs
- Duplication of ETL logic is eliminated
- Risk of transcription or aggregation errors is significantly reduced
These reports deliver insights on clinic attendance (e.g., number of mothers per visit), prevalent maternal conditions, and performed procedures, all derived from the unified patient timeline.
Extending the Pipeline
Once the Patient Timeline is in place, additional ValuePoints reports (e.g., program adherence, outcome measures) can be implemented by building on the base tables and models.
Footnotes
MedInfo 2023;1:e43847: Defines an “event data” model similar to patient timelines.↩︎
MedInfo 2021;4:e25645: Presents a workflow for filtering and inclusion criteria in clinical event extraction.↩︎
BMC Health Services Research 2023;23:09498-1: Describes methods for integrating data across multiple FHIR resources.↩︎